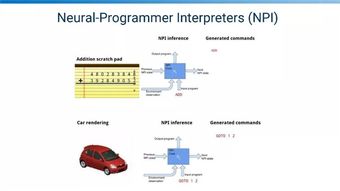
取代Intel!NVIDIA数据中心专用处理器揭秘 一颗DPU顶替125颗x86 CPU,人工智能基础软件开发的革命
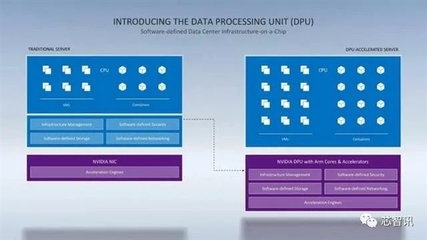
随着人工智能、云计算和超大规模数据中心的迅猛发展,传统的以CPU为中心的计算架构正面临前所未有的挑战。在近期举行的行业发布会上,NVIDIA高调揭晓了其专为数据中心设计的处理器——DPU(Data Processing Unit,数据处理器),并宣称一颗DPU在某些场景下可以替代多达125颗传统的x86 CPU。这一宣言不仅在半导体和云计算领域投下了一枚震撼弹,更预示着人工智能基础软件开发模式将迎来一场根本性的变革。
DPU并非一个全新的概念,但NVIDIA凭借其在GPU领域的深厚积累,赋予了它前所未有的性能与使命。简而言之,DPU是一种高度专业化的处理器,旨在卸载、加速和隔离数据中心基础设施任务,如网络、存储、安全和虚拟化管理。传统上,这些任务由运行在通用x86 CPU上的软件处理,消耗了大量宝贵的计算资源,而这些资源本应用于运行核心业务应用和人工智能模型训练。
DPU的核心优势:为何能“以一当百”?
NVIDIA声称一颗DPU能顶替125颗x86 CPU,其底气来源于DPU的专用化设计。
- 硬件卸载与加速:DPU集成了高性能的Arm CPU核心、强大的网络接口(支持超高速以太网和InfiniBand)以及专用的可编程加速引擎。它能够将网络数据包处理、存储虚拟化、加密解密、防火墙规则执行等任务从主机CPU上完全“卸载”到自身硬件中,并以接近线速的效率执行。这极大地释放了主机CPU的算力。
- 超高的能效比:专用集成电路(ASIC)和针对特定工作负载优化的架构,使得DPU在处理基础设施任务时,其性能和能效远超通用CPU。在数据中心规模下,这意味着巨大的电力节省和碳排放降低。
- 增强的安全性与隔离性:DPU可以在硬件层面创建“零信任”安全模型。它能够管理数据中心的“根安全”,将管理控制面与用户应用数据面严格隔离,即使主机系统被攻破,基础设施本身也能受到保护。
对人工智能基础软件开发的深远影响
DPU的普及将深刻重塑人工智能基础软件的开发、部署和运行方式。
- 释放AI算力瓶颈:在AI训练和推理集群中,CPU常常成为瓶颈,忙于处理数据移动、通信同步(如NVIDIA的NCCL库操作)和存储I/O,而非专注于计算。通过DPU卸载这些任务,GPU和AI加速器可以获得近乎100%的专注时间用于矩阵运算,大幅提升整个AI工作流的吞吐量和效率。开发者可以更专注于算法创新,而无需过度优化底层数据流。
- 重新定义软件栈架构:未来的数据中心软件栈将演变为“CPU+GPU+DPU”的三核驱动架构。系统软件、云计算平台(如OpenStack、Kubernetes)和存储系统(如Ceph)将进行深度重构,以利用DPU的硬件加速能力。例如,虚拟机的热迁移、网络功能虚拟化(NFV)、分布式存储的元数据管理等关键操作,性能将得到数量级的提升。对于AI开发者而言,这意味着更稳定、低延迟和高带宽的数据供给管道。
- 催生新的开发范式与工具链:NVIDIA提供了名为DOCA(Data Center Infrastructure-on-a-Chip Architecture)的软件开发套件。DOCA类似于CUDA之于GPU,它允许开发者利用标准的API对DPU进行编程,轻松调用其硬件加速功能。这使得网络、安全和存储工程师能够像AI科学家使用CUDA那样,高效地开发高性能、可扩展的数据中心基础设施应用。人工智能基础软件与基础设施软件之间的界限将变得模糊,协同优化成为可能。
- 推动超融合与边缘AI:DPU强大的集成能力使得在单台服务器内实现超融合基础设施(HCI)变得更加高效和经济。对于边缘AI场景,DPU可以帮助在资源受限的环境中,更安全、高效地处理数据流,为边缘服务器提供企业级的数据中心能力。
挑战与展望
尽管前景广阔,DPU的普及仍面临挑战。生态系统的构建是关键,需要整个软件行业,特别是操作系统、虚拟化平台和云服务商的广泛支持。开发人员需要学习新的编程模型(如DOCA)。从市场格局看,NVIDIA此举直接挑战了以Intel为代表的传统数据中心CPU霸主地位,Intel也通过IPU(Infrastructure Processing Unit)等产品进行回应,未来的竞争将异常激烈。
总而言之,NVIDIA DPU的推出不仅仅是发布了一款新芯片,更是吹响了数据中心计算架构从“以CPU为中心”向“以数据为中心”全面转型的号角。对于人工智能领域而言,这意味着底层基础设施将变得更加强大、智能和透明,为下一个万亿参数级别的AI模型和更复杂的AI应用,铺平了坚实的硬件与软件基础。一颗DPU替代125颗CPU的故事,正是这场静默革命中最响亮的开场宣言。
如若转载,请注明出处:http://www.wmvpau.com/product/48.html
更新时间:2026-04-16 14:09:07